

机器之机杼剪部
跟着大说话模子渐渐进入复杂推理、自动化研究和收罗安全等高难度任务,传统的模子评测相貌正在濒临新的挑战。
长久以来,模子发布时时伴跟着一张由多项基准测试组成的得益表:数学、编程、科学问答、收罗安全、常识推理等智商被压缩为若干分数,并据此与上一代模子进行横向比较。
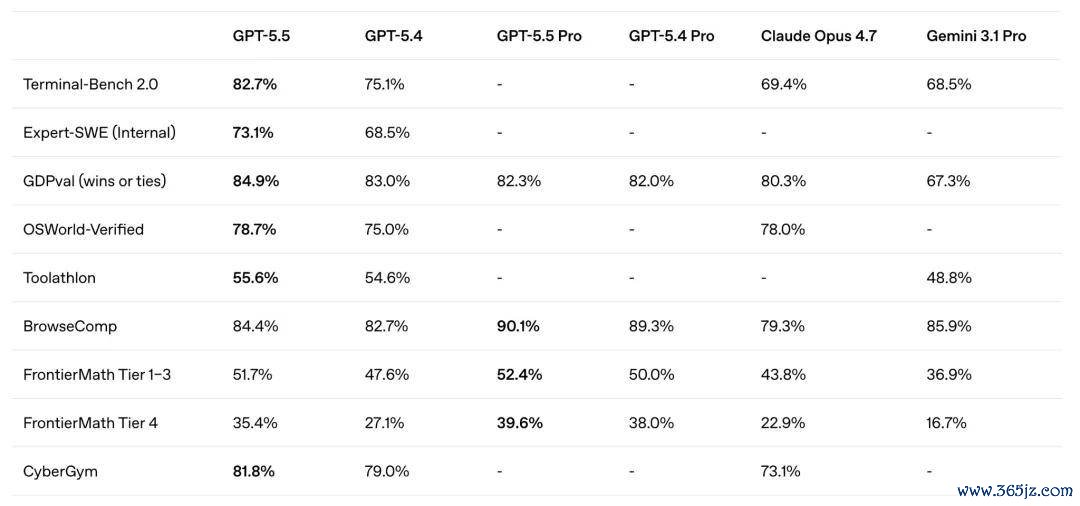
OpenAI 研究员 Noam Brown 近日撰文指出,当模子能够在回复问题时使用更多推理体式、调用更多器用或奉行更永劫辰的搜索与试验后,单一分数已越来越难以准确反应模子的实质智商。
Brown 的中枢不雅点是:大模子的发扬不仅取决于模子自身,也越来越取决于模子在推理阶段获取了几许打算资源。明天评估模子时,不可只问「模子得了几许分」,还应回复另一个问题:模子是在铺张几许 token、几许用度和多长运行时辰的前提下,获取这一得益的?
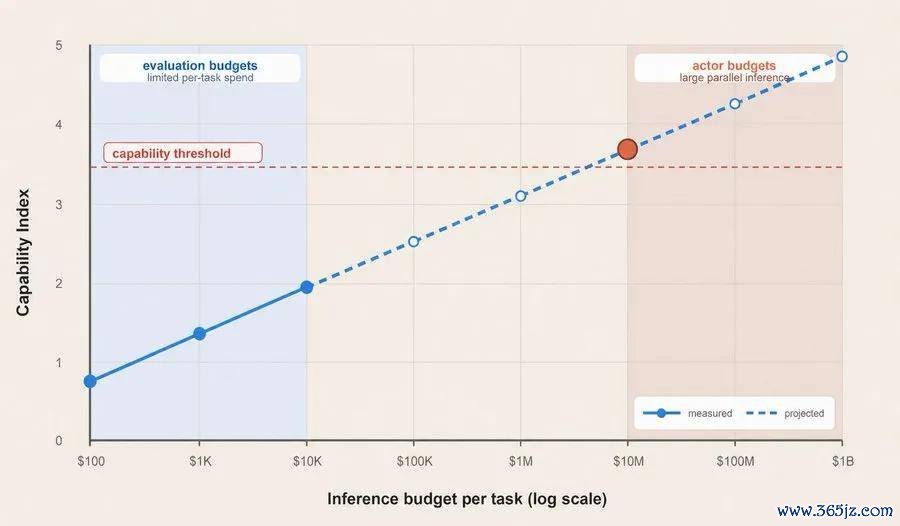
他建议,行业应当从「单点得益」转向「性能—推理打算量弧线」,并将推理预算视为模子智商评估和东说念主工智能安全计谋中的基础变量。
新模子的智商差距,可能被传统得益表低估
Brown 以 GPT-5.5 发布后的市集反应为例,证实传统模子排名榜的局限性。
按照他的刻画,GPT-5.5 发布初期,外界最先防卫到的是一组并不算特等显眼的基准测试得益。与 GPT-5.4 比拟,新模子的分数有所提高,但从通例得益表看,升迁幅度似乎有限。部分用户因此对新版块握不雅望以至质疑气魄。
但在模子绽放使用后的数小时内,跟着开采者和研究东说念主员开动测试更复杂的任务,一些用户发现,GPT-5.5 在长链条推理、握续奉行和复杂问题处理方面发扬出愈加彰着的代际各异。Brown 合计,这种「实质体验彰着增强、榜单分数却变化有限」的气象,反应出传统评测莫得完整呈现模子智商。
问题在于,不同模子的评测收尾巧合确立在疏浚的推理预算之上。
在传统评测框架中,研究者时时会为每个模子选拔一套能够尽可能提高得益的测试设立,再将最终分数放入吞并张表格。这种相貌看似平允,但可能遮盖一个关节变量:某些模子不错在获取更多推理 token、更多调用次数或更长运行时辰后,赓续权贵升迁发扬;另一些模子则可能较早触及性能上限。
Brown 展示的收罗安全评测案例标明,如若只比较各模子在所谓「最大测试时打算量」要求下的最终得益,GPT-5.5 相较 GPT-5.4 的上风可能并不杰出。但如若将 token 数目、推理资本或延迟适度在疏浚水平,再不雅察不同模子的发扬,GPT-5.5 的智商升迁会愈加彰着。
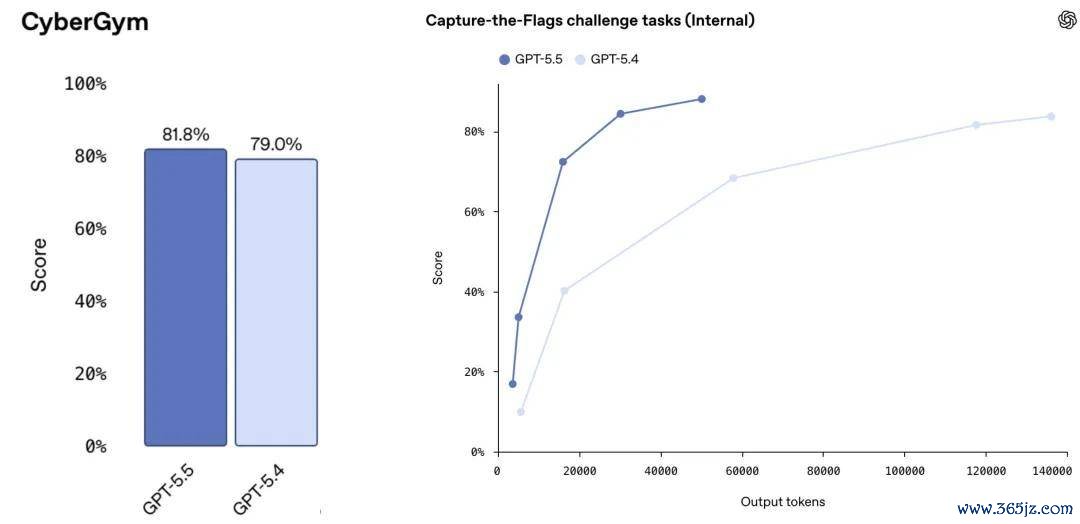
换言之,模子间的差距不仅体现时最终分数上,也体现时其驾驭极端推理打算量的效果上。
为什么不可毛糙地「跑到性能不再升迁为止」
一种直不雅的处置决策是:为每个模子握续增多推理资源,直到其发扬进入平台期,再比较各自的最高智商。
Brown 合计,这种念念路在实践中巧合可行。原因是,关于新一代模子而言,性能平台期可能远比预期更晚出现,以至在实际可承受的预算范围内难以不雅测。
他援用了 Andrej Karpathy 发起的自动化研究实验行为例子。在酌量实验中,模子握续奉行大都试验后,性能仍然保握改善趋势。即使实验次数达到数百次,升迁弧线也莫得都备趋于平稳。
Brown 同期提到英国东说念主工智能安全研究所(AI Security Institute)的收罗安全评测收尾。在该评测中,包括 Mythos 和 GPT-5.5 在内的部分模子,在累计使用杰出 1 亿 token 后,任务发扬仍然赓续提高。
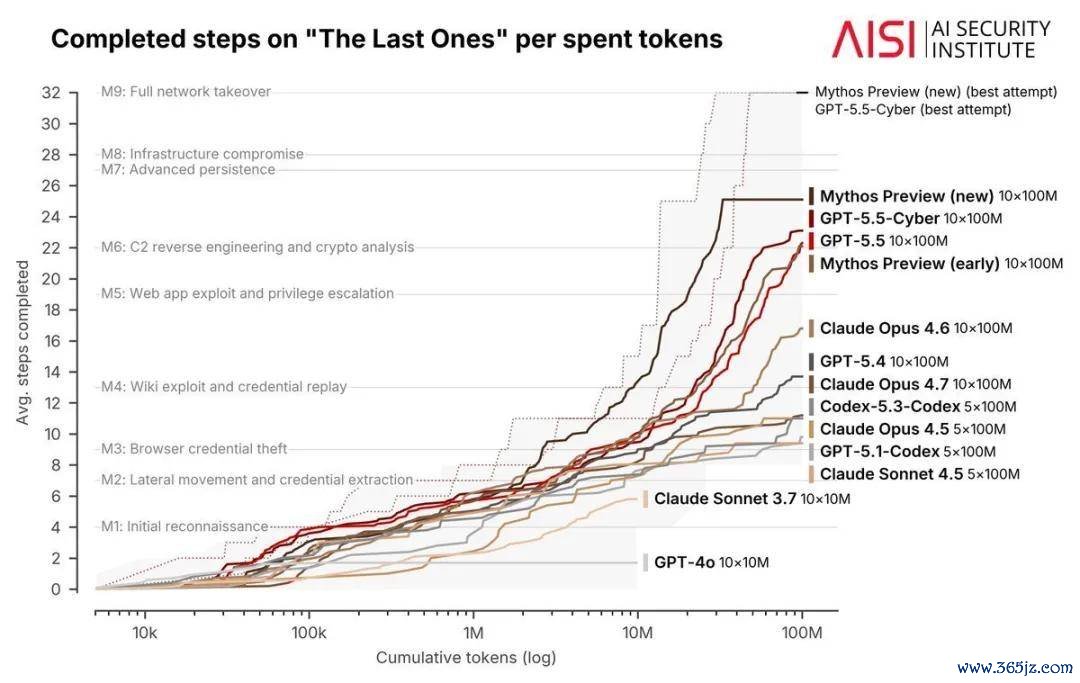
这一气象意味着,在复杂任务上,模子能够驾驭越来越长的运行时辰和越来越大的推理预算,握续探索、试错和修正策略。更强的模子不仅来源更高,还可能更擅长将极端打算资源回荡为有用智商。
Brown 据此计算,跟着模子智商提高,其可有用运行的任务周期也会延长。畴昔,东说念主们大概不错在相对有限的预算下不雅察到模子性能趋于正经;明天,性能上限可能被陆续推远。在某些任务中,所谓「平台期」以至可能不再是一个容易测量的景况。
从单一分数转向「性能—资本弧线」
面对这一变化,Brown 建议,模子发布机构应改动基准测试的呈现相貌。
与其只公布一个最终分数,不如在横轴上标注推理打算量,在纵轴上展示任务发扬,绘图完整的性能变化弧线。横轴不错吸收 token 数目、推理用度或实质运行时辰等筹画。
这种方法能够回复传统得益表难以施展的问题。举例,在疏浚预算下,哪个模子发扬更好?当预算增多十倍时,哪个模子升迁更快?模子是否也曾接近智商上限?不同模子的资本效益如何变化?
现时,部分基准测试也曾开动吸收近似方法。Brown 提到,ARC-AGI 等评测已尝试斟酌模子分数与运行资本之间的关系,而不是只发布单一得益。
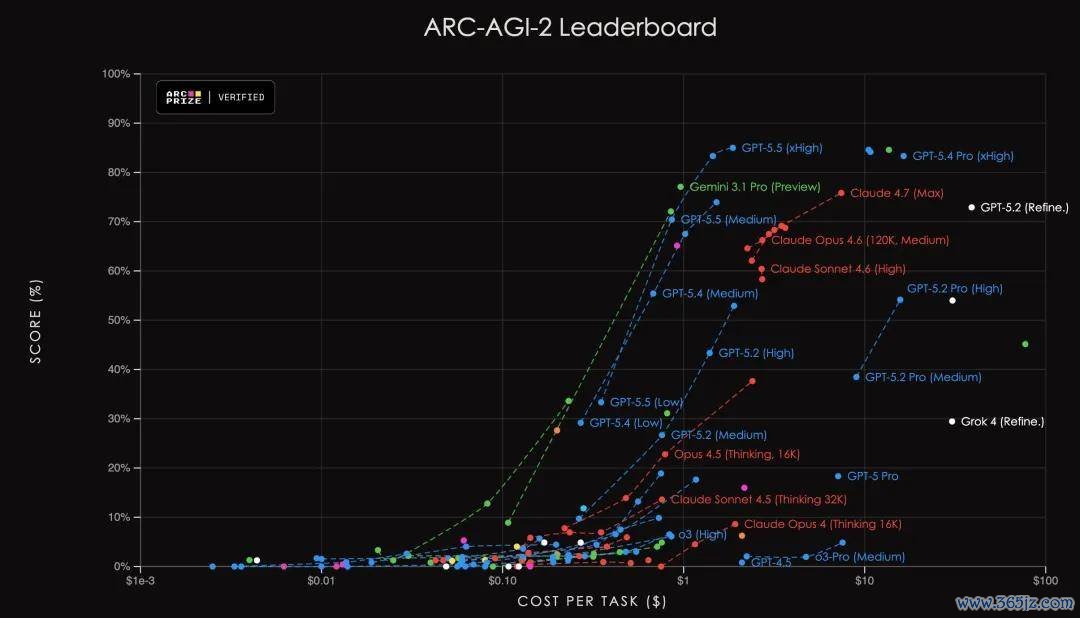
另一种可行决策,是为评测设定明确的 token、资本或时辰端正,并提前将预算信息请问模子。这种相貌近似于东说念主类参加圭臬化考试:不管是好意思国大学入学考试 SAT,如故海外数学奥林匹克竞赛,参赛者都需要在固定时辰内完成任务。模子智商也不错在长入敛迹下进行比较。
不外,Brown 同期指出,不同筹画都有局限。
token 数目巧合能够径直跨模子比较,因为不同模子使用的分词器、生成速率和单元 token 资本可能存在各异。用度受到硬件驾驭率、批量处理相貌和工程齐备的影响。运行时辰相同不是完好筹画,因为「多智能体合作」或 best-of-N 等本领不错并行生成多个候选谜底,在权贵增多算打算量的同期,不一定彰着增多用户感受到的恭候时辰。
尽管如斯,他合计,上述筹画中的任何一种,都比脱离推理预算的单一分数更具信息量。
推理预算问题正在蔓延至东说念主工智能安全评估
Brown 的究诘并不限于模子排名榜。他合计,Kaiyun中国大陆官方网站入口推理预算还会径直影响前沿模子的安全管制。
在前沿东说念主工智能模子发布前,研发机构常常会对收罗袭击、生物风险、化学风险和其他潜在滥用智商进行评估。如若模子达到某一风险阈值,研发机构可能需要推迟发布,或在部署前增多造访端正、监控机制和其他缓解法子。
问题在于,如若模子智商会跟着推理打算量增多而升迁,那么安全评估应当使用多大的推理预算?
在实际中,宽阔用户可能只会为一次任务参加几好意思元或几十好意思元。但一个资金充足的组织、专科团队或国度级行径体,可能景象为单一主义参加远高于宽阔用户的资源。如若评测机构只在较低预算下测试模子,就可能低估其在高资源要求下的风险智商。
Brown 以 Gemini 3 Deep Think 发布后的争议为例。他指出,Deep Think 的基准测试得益权贵高于此前模子,但发布时莫得同步提供针对该版块风险智商的完整系统卡。这一作念法激励部分东说念主工智能安全研究者品评。
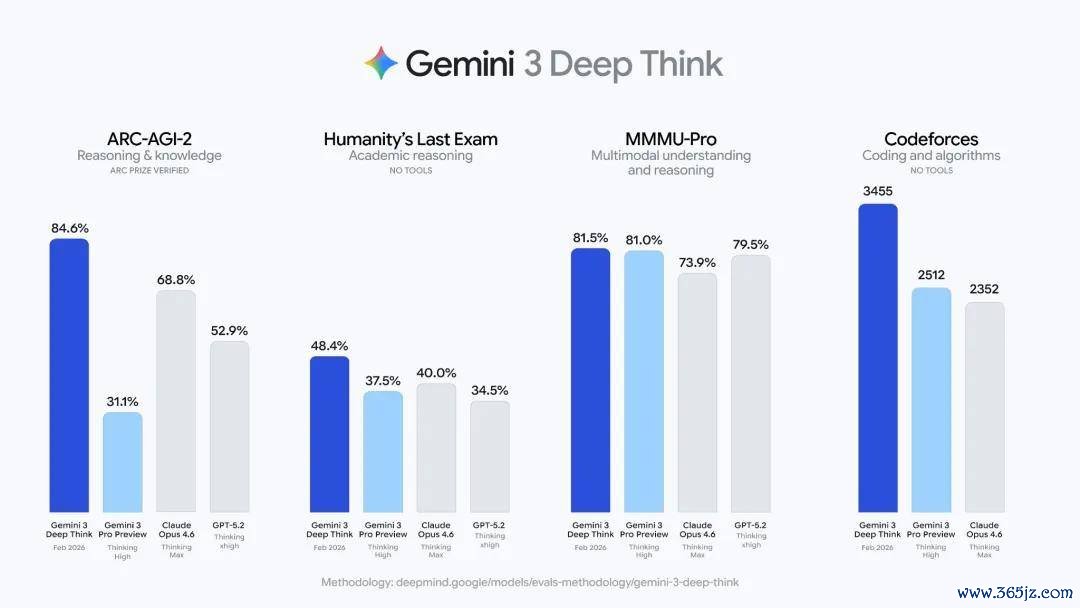
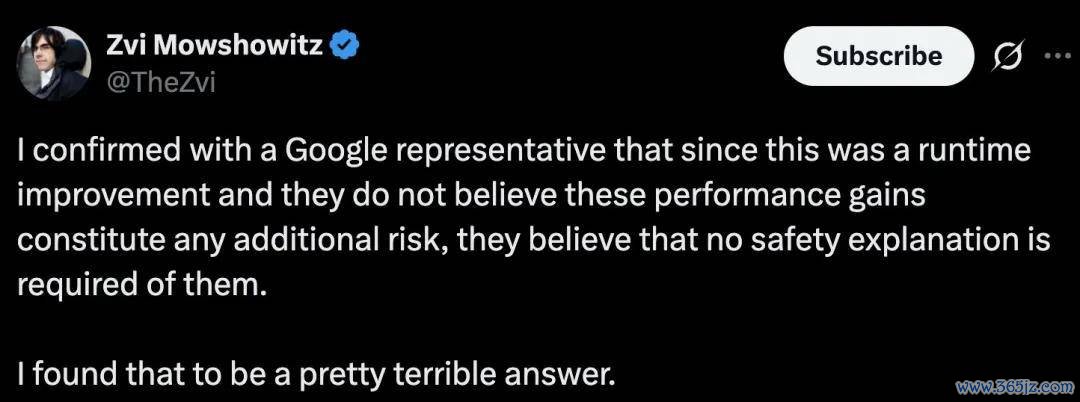
不外,在 Brown 看来,争议背后还有更深层的问题:东说念主工智能企业和安全机构尚未酿成一套正经的方法,用于评估不同推理预算下的模子智商。
他计算,Deep Think 可能并不是一个都备独处教练的新模子,而是基于其他已有模子构建的一套推理脚手架系统。此类系统不错通过屡次调用模子、并行生成候选收尾、自动窥伺谜底和迭代修正等相貌,提高复杂任务发扬。
如若这一判断确立,那么 Deep Think 所展示的部分智商,表面上并非惟一平台自身能够齐备。外部开采者只消景象参加填塞高的推理用度,也可能通过组合屡次模子调用,构建出近似的职责流。Deep Think 的作用,更多是将正本需要专科开采智商的复杂推理历程,封装成宽阔用户也能陋劣调用的居品花样。
因此,Brown 合计,真适值得保养的问题不是某一个居品是否单独发布了系统卡,而是当基础模子当先发布时,研发机构是否也曾充分测试了它在不同推理预算和不同脚手架策略下可能达到的智商水平。
高预算评测难以全面实施,但不错尝试外推
表面上,一个资源充足的行径体可能为单一任务参加杰出 1000 万好意思元的推理资本。但安全评估常常波及千千万万以至数百万次测试运行。如若每一次运行都使用极高预算,评测资本将飞快失去可行性。
Brown 提议,不错先在相对可控的推理预算范围内进行测试,再把柄模子智商随打算量变化的趋势,对更高预算要求下的发扬进行外推。同期,评测机构应明确标注展望区间和不细则性,而不是将推算收尾视为细则论断。
这种方法近似于通过局部数据估算更大鸿沟系统的变化趋势。它无法替代实质测试,但不错匡助研发机构和监管者阐明:当模子被赋予更多时辰、更多器用和更多打算资源后,风险鸿沟可能发生若何的变化。
不外,Brown 也承认,长周期任务仍然可能带来难以通过短期实验处置的问题。
举例,如若研究者但愿判断一个自主智能体在握续运行一年后是否会出现主义偏移、策略欺诈或其他失配行径,那么最可靠的方法可能仍然是让该智能体实质运行填塞长的时辰。只是把柄几小时或几天的实验收尾进行外推,巧合能够捕捉长久行径中的关节变化。
这将产生一个新的实际矛盾:东说念主工智能模子的开采和发布周期可能惟一数月,而智能体能够握续运行的任务周期却可能越来越长。明天,研发机构大概会濒临一种特殊情况——新模子还莫得完成覆盖其最大运行周期的安全测试,下一代模子就也曾接近发布。
三项建议:让推理预算成为模子评估的基础变量
针对智商评测和安全管制中的上述问题,Brown 提议了三项具体建议。
第一,东说念主工智能研发机构应当在发布新模子时,公布不同推理预算要求下的基准测试发扬。设想情况下,企业应提供以 token 数目、资本或运行时辰为横轴的性能弧线。至少,企业需要证实取得某一单点得益时实质使用了几许推理资源。
第二,基准测试排名榜应当纪录推理资源铺张,或者为参评模子设定长入的 token、用度或时辰上限。现时,也曾有部分评测开动纳入酌量变量,但行业尚未酿成圭臬作念法。
第三,东说念主工智能企业的准备度框架(Preparedness Framework)和负背负扩张计谋(Responsible Scaling Policy,RSP)应当明确接头推理阶段的打算资源。当机构判断模子是否进步某一安全阈值时,不应只检会单一设立下的发扬,还应评估多个推理预算水平,并对更高预算要求下的风险智商进行带有不细则性证实的展望。
行业已判辨到问题,但评测体系仍未都备跟上
推理阶段增多打算资源不错升迁模子发扬,并不是一个全新的发现。
自 OpenAI 在 2024 年 9 月发布 o1 系列推理模子以来,行业也曾普遍判辨到:模子在回复问题时参加更多推理体式,能够在数学、代码和复杂分析任务上取得更好的收尾。围绕「测试时打算扩张」或「推理时打算扩张」的研究,也逐步成为大模子发展的遑急标的。
但 Brown 合计,在这一趋势出现近两年后,很多前沿模子发布仍然主要依靠单一基准分数进行传播和比较。部分安全机构也可能在某个脚手架系统使用数十倍、以至上百倍推理预算获取更高得益后,才再行注目模子智商鸿沟。
跟着模子越来越擅长驾驭永劫辰运行、多轮试错和大鸿沟推理资源,传统排名榜的施展力可能赓续下落。吞并个基础模子,在低预算问答、高预算深度研究、多智能体合作和自动化器用调用等不同要求下,可能呈现出毫不疏浚的智商水平。
Brown 的判断是,明天斟酌东说念主工智能智商时,推理预算不应再被视为测试过程中的附属信息,而应像模子鸿沟、教练数据和陡立文窗口一样,成为评测敷陈中的中枢参数。
从更无为的角度看,这也意味着,东说念主工智能行业正在渐渐告别「用一个数字界说一个模子」的阶段。关于智商评估、居品比较和安全管制而言,简直遑急的问题可能不再只是模子能作念什么,而是当它获取填塞多的时辰、资金和打算资源后,究竟不错作念到什么进程。
参考连结:https://x.com/polynoamial/status/2064210146558136827kaiyun.com
 备案号:
备案号: